
お仕事でAWSを使っています。
そんなAWSに2021年05月にSystems Managerの機能としてIncident Managerが登場しました。
仕事で運用周りをやっているのもあり、せっかくなのでこのIncident Managerを使って監視システムを作ってみました。
今回の記事では、EC2が停止(ステータスチェックでエラーになった)状態になったことを想定した形で進めています。
Incident Managerとは?
AWSのIncident Managetとは、簡単にいってしまうと
障害発生時のワークフロー(運用フロー)を定義して、(ある程度)自動化する
ためのものです。
サービスとしては、Systems Managerの中の一項目になります。
AWSの説明は以下の記事を読んでいただくとわかります。
参考
AWS Systems Manager の Incident Manager のご紹介Amazon Web Services
AWSのすごいなというか考えているなぁというのはこういった自動フロー的な部分をできるだけ自分たちのサービス(機能)の中で対応しようとするところです。
障害検知のトリガーから通知・対応・チケット管理を他のAWSのサービスを組み合わせながらある程度の形を作ることができます。
もちろん、外部サービスへの連携もできるようになっています。
実際にどんな感じなのか、一つ例を使いながら説明をしていきます。
Incident Managerを使えるようにする
今回は、Incidenet Managerを一から設定していって、模擬的に障害を発生させて、復旧するまでをやってみました。
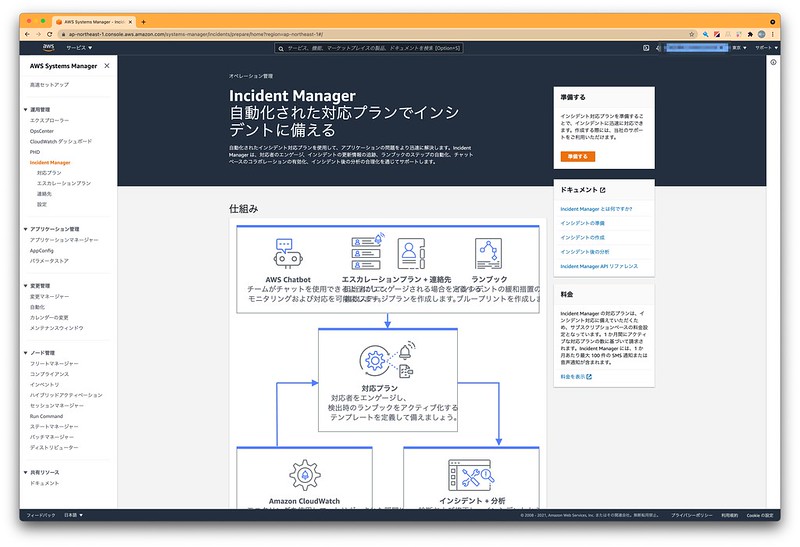
▲Systems Managerを選択すると、左側ペインに「Incident Manager」があるのがわかると思います。
今回は、左側ペインをクリックして表示される初期画面にある、「準備する」をクリックして進めます。
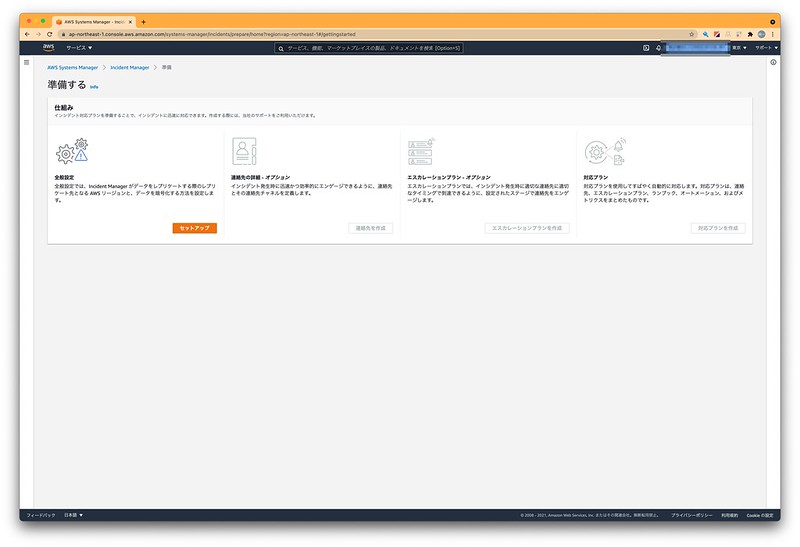
▲全体設定欄にある「セットアップ」をクリックして先に進めます。
すると、利用規約の画面が表示されます。
▲利用規約の内容を確認して、同意して先に進めます。
現状使っているリージョンが選択された状態です。
別リージョンにもIncidentManagerを構築して災対的な仕組み(リージョン障害に対応する)こともできます。
今回は検証だけなので、災対リージョンは選択せず、シングルで進めていきます。
しばらくすると利用可能状態になります。
誰の連絡先かがわかるように設定しておきます。
連絡先の種類として、以下3つが選べます。
- Eメール
- SNS
- 電話
一つの連絡先で全て登録することも可能です。
今回は私一人しか登録しないので、各連絡先の検証に全部登録しました。
なお、それぞれの連絡先の手段に対してアクティベーションコードが届きます。
それをそれぞれの欄に入力する必要があります。
これが「エスカレーションプラン」と呼ばれるものになります。
運用をやっている人にはイメージがつきやすいですが、発生した自称に対してどう連絡(エスカレーション)していくか?を決めるものです。
合わせて連絡のタイミングを決めるのですが、この辺りはもう少し検証してみる必要がありそうです。
とりあえず時間をおいて指定された連絡先に連絡できることまでは確認済みです。
名前やタイトルは表示された時に識別しやすい名前をつければ大丈夫です。
続いて影響度の設定です。
この辺りはITILのインシデント管理だったり、お客様などで運用している障害対応にもでてくるので、設定できるのはありがたいですね。
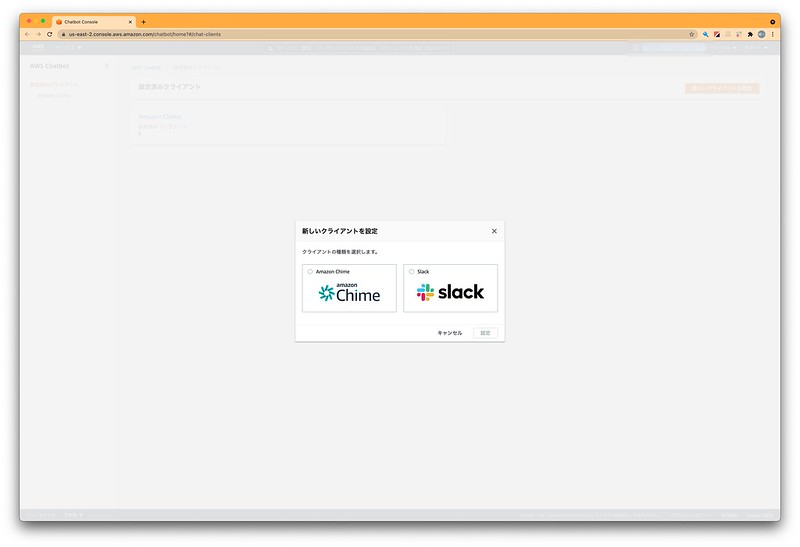
▲チャットのチャンネルにはAmazon ChimeかSlackが選べます。
Slackは事前にチャンネルを作っておく必要があります。
ワークスペースのURLを入力して、アクセス許可を追加します。
ですのでSLackのワークスペース管理者権限がないと設定できないです。
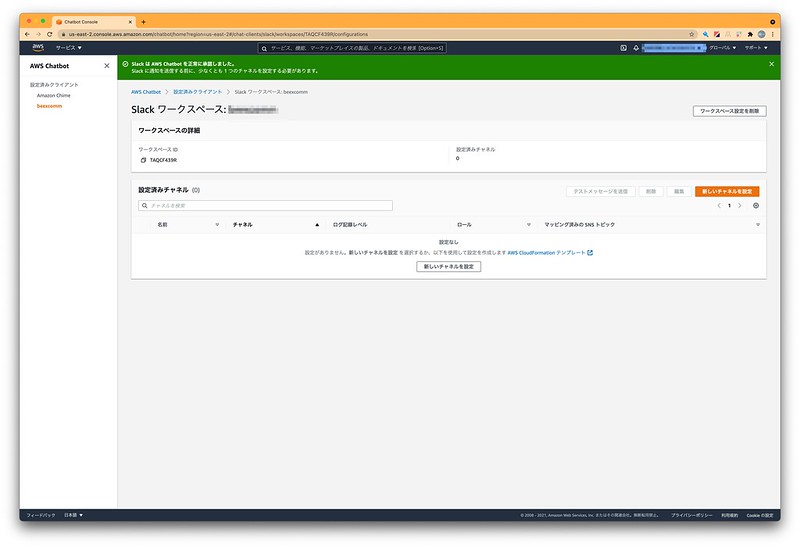
▲どのチャンネルに投稿するかなど設定していきます。
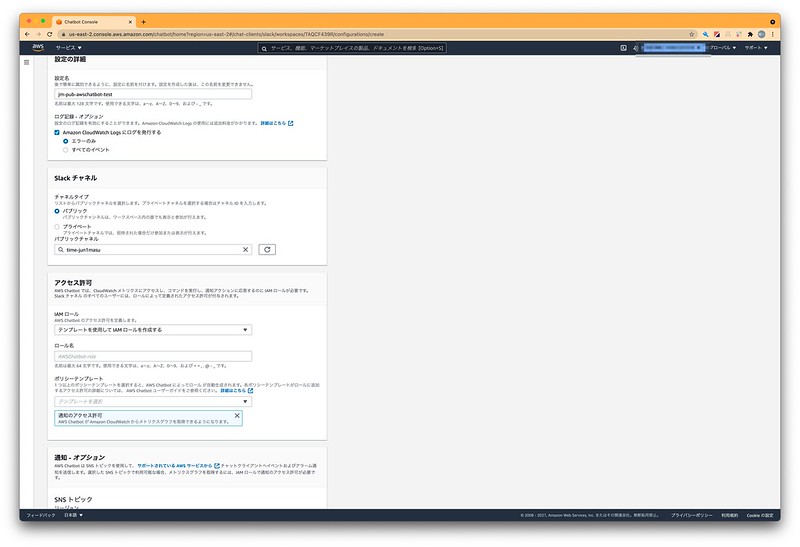
▲登録したSlack情報を対応プランで設定します。
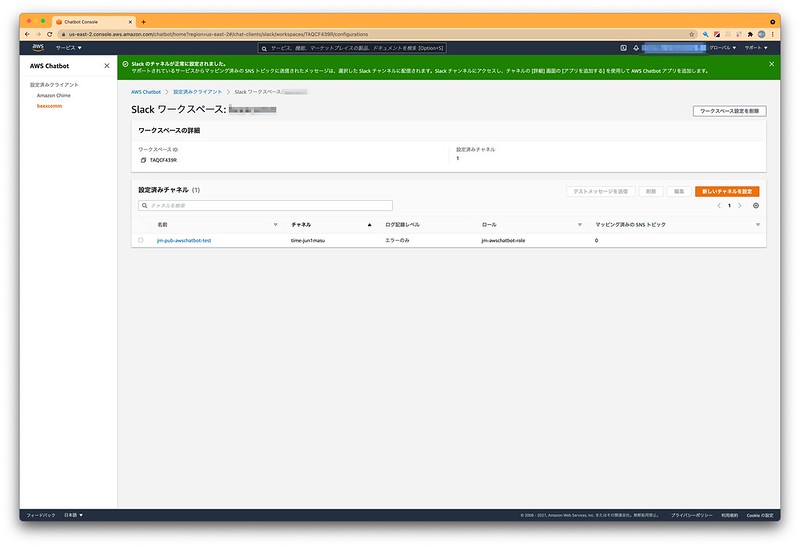
▲先ほど作ったエスカレーションプランを紐付けます。
これで該当するインシデントが発生した場合に連絡フローが流れるようになります。
続いてランブックと呼ばれる、インシデント発生時の自動実行定義を指定します。
ここについては、既にAWSが用意してくれているものもありますし、自分で作成したものを指定することもできます。
EC2の停止や起動といった基本的なものは手間を省くためにAWS提供のものを使うと工数が削減できますね。
複数のサービスを操作したり、細かくログを残したりしたい場合には自分で作成しましょう。
実行するためのRunブックに付与するIAMロールの作成が必要なので、ここで一旦IAMからロールを作成します。
必要な権限は、「ssm:StartAutomationExection」になります。
Switchロールして運用している環境ではキャプチャのように、「AssumeRole」も追加が必要になります。
IAMロールの書き方としてはいかになります。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"iam:PassRole",
"ssm:StartAutomationExecution"
],
"Resource": [
"arn:aws:ssm:*:[AWSアカウントコード]:automation-definition/[使いたいRunBook名]:*",
"arn:aws:ssm:[リージョン]::automation-definition/[使いたいRunBook名]:*",
"arn:aws:iam::147853291576:role/[作成しているロール名]"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::*:role/[作成しているロール]"
}
]
}
この時に注意点が一つ。
AWS提供のランブックを利用するときは、ARNの中のアカウントコードの部分が異なるので注意してください。
これで私はハマってしまって何度やってもうまく実行できずにハマってました。
作成したロールを実行権限として対応プランにて選択しましょう。
これでIncident Managerの設定は完了しました。
実際にどういう動きをするかを確認してみましょう。
EC2にアタッチされているネットワークインターフェースをダウンさせて、システムチェックをエラーにすることでインシデントを発生させます。
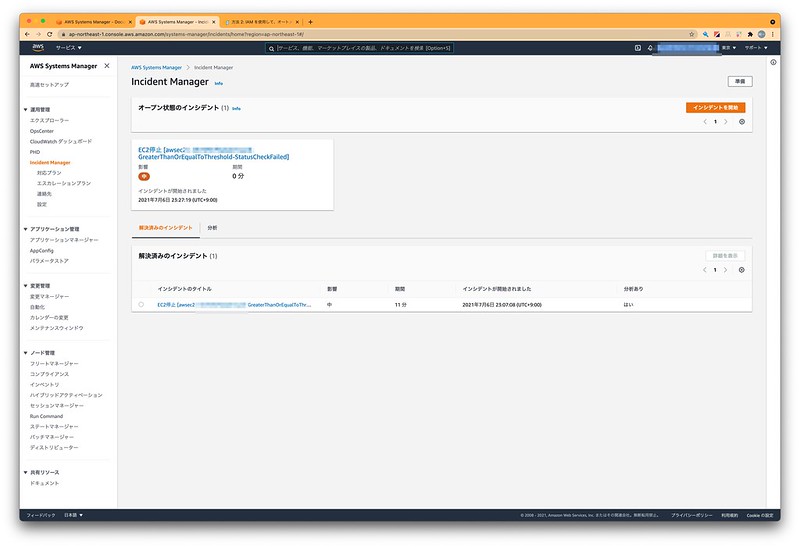
▲システムチェックがNGになるとこのようにIncidentManagerに表示されます
あとは設定した通りに連絡フローだったりランブックの実行が行われていきます。
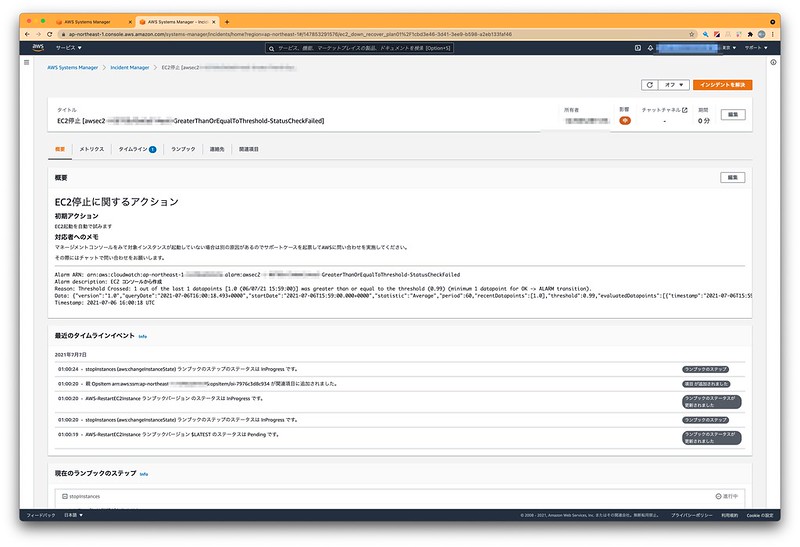
▲概要部分に記載していた対応メモが表示されるので、対応手順を記載しておけば運用メンバーに同一手順での対応をお願いすることもできます。
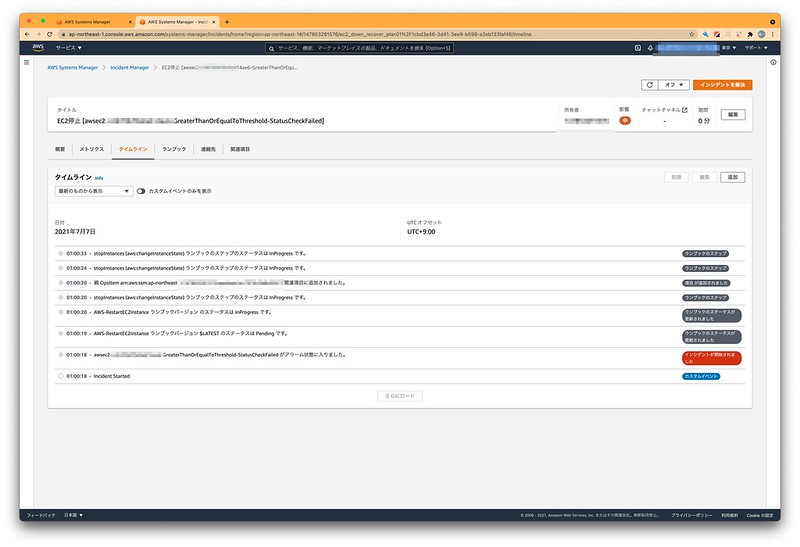
▲タイムラインでは時系列に発生した事象に対してのアクションが確認できるので、何をどうしたかの確認ができます。
後からこれをみて対応のよくなかったところや改善を検討することができるので便利です。
大規模ではないけど運用を楽にしたい環境ならIncident Managerが有効だと思った
ざっと設定をしてつかってみた印象としては、
小規模の監視対象を少人数で運用するなら便利
というところです。
アラートの設定を今のところは各監視対象に設定する必要があります。
つまり台数分設定・変更が必要になってくるということです。
なので数が多くなってくるとその分の設定や変更が必要であり運用コストが上がってきます。
数が多い場合には、ZabbixやDataDogといったもので集中管理してアラートに対してアクションしていく方が効率的です。
この辺の考察はまた別記事にできればと思います。
AWSのリソース(サービス)監視したいけど、大々的にはできないけど、なんか監視しておきたいって時には、まずIncident Managerを使ってみるのはおすすめです。